Terraform state 概論
この記事は terraform Advent Calendar 2019 - Qiita の 14 日目です。
Terraform State (以下、本記事では tfstate と呼称します)をご存知でしょうか。 Terraform を使っていて tfstate をご存知ではない人はまぁまずいないはずだとは思いますが、直接の編集が非推奨となっているためデリケートな扱いが求められる一方で、 Terraform を使っていると折に触れて立ち向かわなくてはならない憎いやつです。
Terraform を上手く使うことは、 tfstate を上手く取り扱うこととニアリーイコールだと個人的に思っています。そんな tfstate のことをいろいろとまとめてみました。ていうかまとめすぎてえらいことになったので、年末年始のお暇なときにでも読んでみてください。
全体は以下4つに分かれています。
- tfstate 入門 : 文字通り入門的な内容です。
- tfstate 理論 : tfstate にまつわる Terraform の挙動に関して理論的な内容です。
- マクロ tfstate 論 : マクロな視点で考えた、 tfstate の運用管理プラクティスです。
- ミクロ tfstate 論 : ミクロな視点で考えた、 tfstate の編集などの話です。
tfstate 入門
本項では tfstate の基本的な性質、特徴について触れていきます。
tfstate の基礎
tfstate は Terraform が管理するインフラストラクチャーの状態をプレーンテキストで保存したファイルです。データ構造は Terraform の他の設定ファイル(以下、 tffile と呼称します)とは異なり、 JSON が用いられています。
tfstate は自動生成されるファイルであり、手動で書き換えることは非推奨とされています。具体的なタイミングとしては terraform apply コマンドが実行された際に新規作成、もしくは既存のものが更新され、 apply した結果構築、変更されたインフラストラクチャーの状態が記録されます。
また terraform plan コマンドが実行された際には、 tfstate から前回 apply 実行時のインフラストラクチャーの状態を読み取り、それと設定ファイルに記載されたインフラストラクチャー設定との差分から plan 結果を出力します。この挙動については後ほど詳説します。
tfstate の保存場所
特に設定していなければ、デフォルトの保存場所は terraform apply を実行したカレントディレクトリ上の terraform.tfstate という名前のファイルになります。しかし、先述の通りこのファイルは次回 apply 実行の際に必要となります。ローカルに置いたままでは複数人で terraform を実行できなくなってしまうため、何らかの手段で共有する必要があります。
共有する上で、 VCS を用いることは非推奨とされています。これは例えば複数人が git clone して同時に terraform apply を実行してしまった場合などに、競合が発生する可能性があるからです。 tfstate は常に唯一無二のファイルがどこかに存在し、誰もがそのファイルを参照する必要があります。
そのため tfstate の保存にはオブジェクトストレージ等を用いることになります。これを設定するのが backend という設定です。
1terraform {
2 backend "s3" {
3 bucket = "example"
4 key = "tfstate/terraform.tfstate"
5 region = "ap-northeast-1"
6 }
7}
上記の設定では Amazon S3 を backend として指定しています。この設定を記載した状態で terraform init を実行すると、 backend へのアクセスが可能か確認され、問題なければ plan や apply の際にこのパス上のファイルを tfstate として取り扱うようになります。
backend に指定可能なストレージは Terraform がサポートしているものに限られますが、 Azure BLOB Storage 、 Google Cloud Storage といった、メジャーなクラウドサービスの各オブジェクトストレージにはいずれも対応しています。また 2019 年からは、 Terraform を制作した hashicorp が backend サービス Terraform Cloud を公開しており、ユーザー5人までのチームであれば、無償で利用することも可能です。
tfstate は何のために存在するのか
tfstate という仕組みが設けられている理由はいくつかあり、詳しくは State - Terraform by HashiCorp に解説されています。ここでは「Terraform の管理対象を明確化する」という点について考えてみます。
すでに EC2 インタンスが 4 台動いている AWS アカウントに、 Terraform を実行してもう 1 台インスタンスを追加した場合を考えます。次に plan したとき、 tfstate があれば、前回構築したインスタンスの ID が記録されているので、そのインスタンスとの差分を確認すればよいことになります。しかし tfstate が無いとすると、 5 台のうちどれが前回構築したインスタンスかわからず、差分を取ることが困難になります。また、 Terraform は前回実行時以降に tffile から削除したリソースは、現実のリソースも削除しようとしますが、前回実行時の記録がなければ、残る 4 台のインスタンスは Terraform が構築したものなのか、そうでないのか判別ができません。
このように、 tfstate は Terraform の管理対象を明確化してくれます。逆に言えば、AWS アカウント内のすべてのリソースを1つの tfstate で管理対象とするのか、例えばサービスごとだったり、システムの構成単位ごとだったり、何かしらの単位で tfstate を分割していくのかは、個々のユースケースに併せて考えていく必要があります。
もうひとつの tfstate
ところで、あまり意識することはありませんが、 tfstate はもう1つあります。 terraform init 実行時に作成される ./.terraform/terraform.tfstate です。
このファイルにはリソースの情報ではなく、 backend の情報が含まれます。terraform init では backend との疎通確認が行われますが、その結果が問題なければ、 backend 設定がこのファイルへ出力されます。この tfstate は init 実行時に動的に生成されるため、永続的に保存しておく必要はありません。
tfstate 理論
本項では、 tfstate が Terraform によって実際どのように用いられているのか、理論的な部分(?)に触れていきます。
tfstate のファイル構造
手動で読み書きする機会が基本的には存在しないので、案外 tfstate の内容を目にする機会はないのかもしれません。改めて紐解いてみると、以下のような構造をしています。
1{
2 "version": 4,
3 "terraform_version": "0.12.18",
4 "serial": 3,
5 "lineage": "XXXXXXXX-XXXX-XXXX-XXXX-f4e9614b100e",
6 "outputs": {
7 "example": {
8 "value": "example",
9 "type": "string"
10 }
11 },
12 "resources": [
13 {
14 "module": "module.iam.module.core",
15 "mode": "managed",
16 "type": "aws_instance",
17 "name": "example",
18 "provider": "module.example.provider.aws.example",
19 "instances": [
20 {
21 "schema_version": 0,
22 "attributes": {
23 "arn": "arn:aws:ec2::...",
24 ...
25 }
26 }
27 ]
28 }
29 ]
30}
各項目の意味はドキュメントがあるわけではないのであんまりわかっていません。上部に書かれているのはいずれもメタ情報にあたるようで、キーになりそうなのは serial ぐらいかと思います。これは版番号を表しており、 terraform apply によって tfsate が書き換えられるタイミングでインクリメントされます。また terraform_version は、この tfstate が生成される際に用いられていた Terraform のバージョンです。これより古いバージョンの Terraform でこの tfstate を扱おうとすると警告が出て実行できません。特に手動で Terraform を実行している場合、実行者間でバージョンを合わせる必要があるので注意が必要です。
肝になるのはその後の outputs と resources です。 outputs は文字通り Terraform で outputs を設定している場合に限り、その値が記述されます。 resources が、実際に Terraform が構築したリソースの設定情報を記述したオブジェクトの配列です。各オブジェクトの主な項目は以下のとおりです。
module: 該当 resource が module に内包されている場合、その module 名(内包されていない場合はこの項目自体存在しません)mode: data, managed(生成した resource)のいずれかtype: resource typename: resource nameprovider: その resource 生成に使われた Terraform provider 名instances: 最後にterraform applyを実行した時に適用された設定情報の配列
各 resource オブジェクトには type と name が含まれますが、これによって Terraform 設定ファイルに記載している resource と紐ついています。以下の Terraform resource で言えば、 aws_instance が type で foobar が name に当たります。
1resource "aws_instance" "foobar" {
2 ...
3}
また instances 内には、 aws_insntace であればインスタンスIDなどの、現実のリソースを一意に特定する情報が含まれます。これにより resoruce オブジェクトは Terraform resource と現実のリソースとの1対1対応を定義しています。なお、お気付きの通り instances は配列です。 for_each や count を使った場合など、1つの resource block で複数のインフラリソースを構築した場合には、複数のリソース情報が入ります。
terraform plan と tfstate
terraform plan を実行した際には、 tfstate を元にして設定ファイルと現実のインフラとの差分が導かれます。とはいえ、 tfstate に書き出された設定を、直接 terraform 設定ファイルの内容と比較して差分を出しているわけではありません。 tfstate からは、先述のように各 Terraform resource と対応する現実のリソースが存在するのかどうかを読み取るだけです。そして存在していれば、その設定情報を API などを用いて実際に取得し、設定ファイルとの比較を行うことになります。もしも Terraform resource に対応するリソースの情報が tfstate に存在しなければ、そのリソースは新規作成するべきものと判断されます。
つまり、 terraform plan の挙動を表にまとめると以下のようになります。
あるリソースが……
| tffile に | tfstate に | 現実のリソースと tffile の差異が | plan 結果は |
|---|---|---|---|
| ある | ある | ない | No changes |
| ある | ある | ある | change |
| ある | ない | 差異は確認しない | add |
| ない | ある | 差異は確認しない | destroy |
従って tfstate の resources[].instances を仮に手動で書き換えても、 terraform plan の結果は変動しません(インスタンス ID のような、そのリソースを一意に特定する項目は除きます)。それでは tfstate を現実のリソース状態に合わせる terraform refresh は不要なのではないかと思われそうですが、例えば Terraform で構築したリソースを GUI から手動で削除してしまったような場合には、 refresh によって tfstate からも削除の上で、設定ファイルから削除する操作が必要になってきます。
マクロ tfstate 論
本項ではマクロに見たときの tfstate について、具体的には tfstate の運用方法などについて触れていきます。
tfstate の保存場所
「入門」で記したように、 tfstate の保存場所として利用できる backend には様々な種類のものが用意されています。それでは、この中でどれを選ぶべきなのでしょうか。
2019年末の時点においては、 Terraform Cloud がベストと考えています。その理由を1つずつ見ていきます。
フルマネージドであるということ
tfstate を保存するためだけに作られた、フルマネージドのストレージであるという特徴はやはり強みとして大きいです。 Terraform Cloud は以下の機能をもっています。
- 自動的にいつ誰が実行したか履歴を蓄積してくれる
- tfstate 保存場所をわざわざ作る必要がない
- Terraform Cloud が Terraform 自動実行の機能も備えている
1点目について。履歴を自動的に追跡し、誰がいつ apply を実行したかがわかるほか、あまり必要となる機会はないものの、各回での tfstate の差分も見ることができます。
2点目については、例えば S3 だとバケットをあらかじめ作成する必要があるわけですが、 Terraform Cloud の場合は一度アカウントだけ作ってしまえば、その後は保存場所を手で作ったりする必要がありません。3点目については tfstate 保存の問題とは直接関係しませんが、 Terraform Cloud は Terraform 自動実行の機能も備えるなど、 hashicorp が提供しているだけあって Terraform を運用する上で便利な機能が備えられています。それら機能をすぐには使わないとしても、いつでも使えるよう tfstate だけは保存しておく、というのはアリだと思います。
Remote State の利便性を活かしやすい
Terraform Cloud を使う場合の利点として、より重要なのは Remote State の利便性を活かしやすい点にあると考えています。
Remote State とは、別の tfstate が output している値を読み取り、変数として活用できる Terraform の機能です。例として、 AWS のネットワークを構築する際、以下のように output を設定しておくと、他の Terraform からこの値を読み取ることができます。
1resource "aws_vpc" "example" {
2 cidr_block = "192.0.2.0/24"
3}
4
5output "example_vpc_id" {
6 value = aws_vpc.example.id
7}
先に少し触れましたが、 AWS アカウント全体を1つの tfstate が管理下に置くのではなく、いくつか分割する場合がありますが、その場合でもこの機能を使えば相互に値を参照し合うことができます。あるいはマルチアカウント構成の場合でも、他のアカウントから設定値を読み込むことができるのは非常に便利です。 VPC Peering を行う場合などに重宝します。
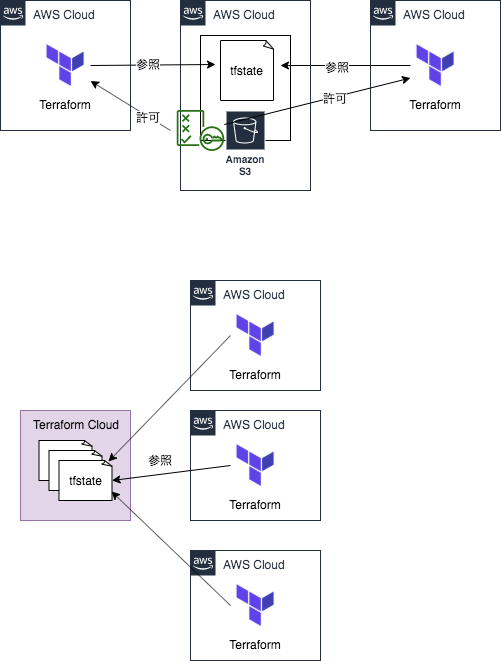
Remote State から設定値を読み出す場合、当然ながらその tfstate に対する読み取り権限が必要になります。仮に S3 に置いている場合、バケットポリシーを適切に設定して、クロスアカウントでの読み取りを許可する必要が出てきます。
これを Terraform Cloud に変えると、 Terraform 実行者は誰もが Cloud 上のすべての tfstate を参照し合うことが可能になります。 tfstate をあえて管理対象クラウドの外に引っ張り出して集めておくことにより、集約的な設定データベースのように取り扱うことができます。
ミクロ tfstate 論
本項ではミクロに見た tfstate として、ファイルの編集処理に着目します。
既存リソースの取り込み
Terraform を扱う上で鬼門になる要素の1つに、「既存リソースの取り込み」があります。 tffile を書かなくてはならないのと同時に、 tfstate にも記述を加えなくてはならない点が厄介です。
この問題を解決するために dtan4/terraforming や GoogleCloudPlatform/terraformer が開発されてきました。これらのツールで対処可能であれば、ツールを利用するのが手早いと思います。ツールが残念ながら対応していないリソースを取り込みたい場合には、 terraform import コマンドを使うことになります。
terraform import は tfstate への取り込みだけを行う機能で、 tffile は作成してくれませんが、ある程度工夫することで楽はできます。まず、 tffile に Terraform resource の枠だけ作成してから terraform import を実行します。枠とは以下のように attributes を何も書き込まない状態です。 import は、対応する resource の記述が tffile に存在していないと動作しないため、 import 実行前にこれだけは必要になります。
1$ cat main.tf
2resource "aws_lambda_function" "example" {
3}
4
5$ terraform import aws_lambda_function.example exampleFunction
6aws_lambda_function.example: Importing from ID "exampleFunction"...
import が完了次第、 import した resource を引数にして terraform state show を実行します。するとこのように、 tfstate の記述を元にして、現在の設定情報が HCL の形で出力されます。
1$ terraform state show aws_lambda_function.example
2# aws_lambda_function.example:
3resource "aws_lambda_function" "example" {
4 arn = "arn:aws:lambda:ap-northeast-1:999999999999:function:exampleFunction"
5 function_name = "exampleFunction"
6 handler = "Handler"
7 id = "exampleFunction"
8 invoke_arn = ...
9 last_modified = "2019-12-13T03:35:41.026+0000"
10 memory_size = 512
11 ...
12
13 timeouts {}
14
15 tracing_config {
16 mode = "PassThrough"
17 }
18}
あとはこれをコピペして tffile を fix すれば取り込み完了です。 terraform state show が v0.12 より HCL 形式で出力されるようになったことで、取り込み処理が非常に楽になりました。注意点として、この HCL には tffile には必要のない attributes references に該当する値も含まれています。そのままにしていても害はありませんが、不要な値を持っておくべきでもありませんので削除しておきましょう。 attributes references について詳しくは、本ブログの Terraformer が import した resource は不要な属性を含む場合がある · the world as code を参照してください。
tfstate の保存場所を変更したい
tfstate を現在の保存場所から別の場所へ移したい場合があると思います。最近であれば Terraform Cloud がローンチされた際、 S3 などから移行した方は多かったでしょうし、 S3 内でファイルの key(パス)だけ替えたいといった需要もあるかと思います。
この操作は意外と簡単で、まず一度 terraform init を実行してから、 tffile の backend の部分を移行先のパスに書き換えてもう一度 terraform init を実行するだけです。 Terraform が以下のように backend の変更を検知して、 tfstate ファイルを移動させるか尋ねてくれます。これを承諾すれば、 Terraform がファイル移動を賄ってくれます。
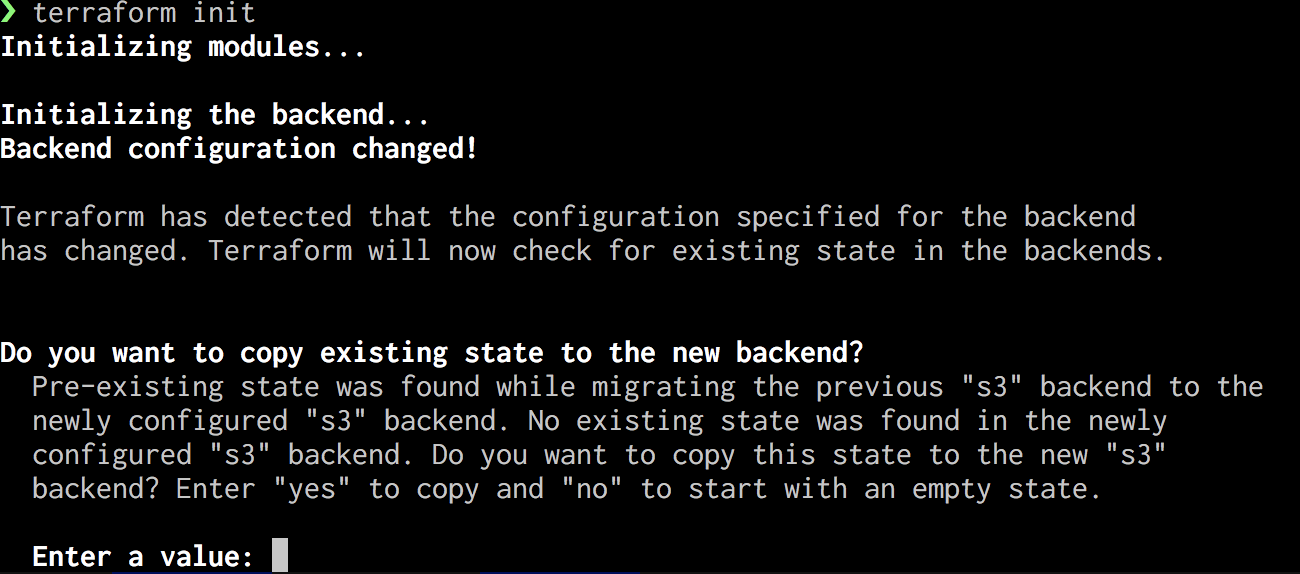
これは「入門」の項で記載した ./.terraform/terraform.tfstate に書かれた backend 設定と、 tffile に書かれた backend 設定に差異があったとき、 backend が変更されたとみなして実行される処理です。
tfstate の編集
tfstate の編集が必要になるのは、 tffile、 tfstate、現実のリソースの三者間で乖離が発生してしまい、 terraform plan の結果が予期せぬものになってしまうような場合です。 tfstate が変更されてしまった、というケースは無いものとして考えると、 tffile を変更したか、現実のリソースを変更したか、いずれかの場合ということになります。このうち現実のリソースを変更した場合については、先にも触れましたが terraform refresh コマンドを実行すれば事足ります。
tfstate の編集 - tffile を変更(リファクタリング)した場合
最も手数を要するのが、リファクタリングなどにより tffile 上の resource name を変更したり、 module の構成を変更したりした場合です。 aws_instance.foo を aws_instance.bar にリネームした場合、 tfstate 上の foo は tffile 上に見つからないので削除対象とされ、 tffile 上の bar は tfstate 上に見つからないので新規構築対象とされてしまいます。
このようなときには terraform state mv コマンドを使って、変更前の名前から変更後の名前へと移し替えていきます。先の例で言えば
1$ terraform state mv aws_instance.foo aws_instance.bar
となります。この aws_instance.foo のような記述形式は Terraform のドキュメント内で address と呼ばれています。 address の書式は resource type と resource name をドットで繋いだ形です。 module に内包された resource の場合は module.(module 名).(resource type).(resource name) の形になります。 module を入れ子にしていると、さらに module.(module 名).module.(module 名)... と数珠つなぎで繋がっていきます。
mv の対象がかなりの数に上ってくると、 address を手で書いてコマンド実行するのが面倒になってきます。こういうときは一旦 terraform plan を実行してしまいましょう。先に書いた通り、 mv 前の tfstate に残っているリソースは削除対象に、 mv 後の tffile に新しく命名されたリソースは新規構築対象になるので、 will be (destroyed|created) という文字列で grep することで、 mv 前後の address をそれぞれ取得できるはずです。
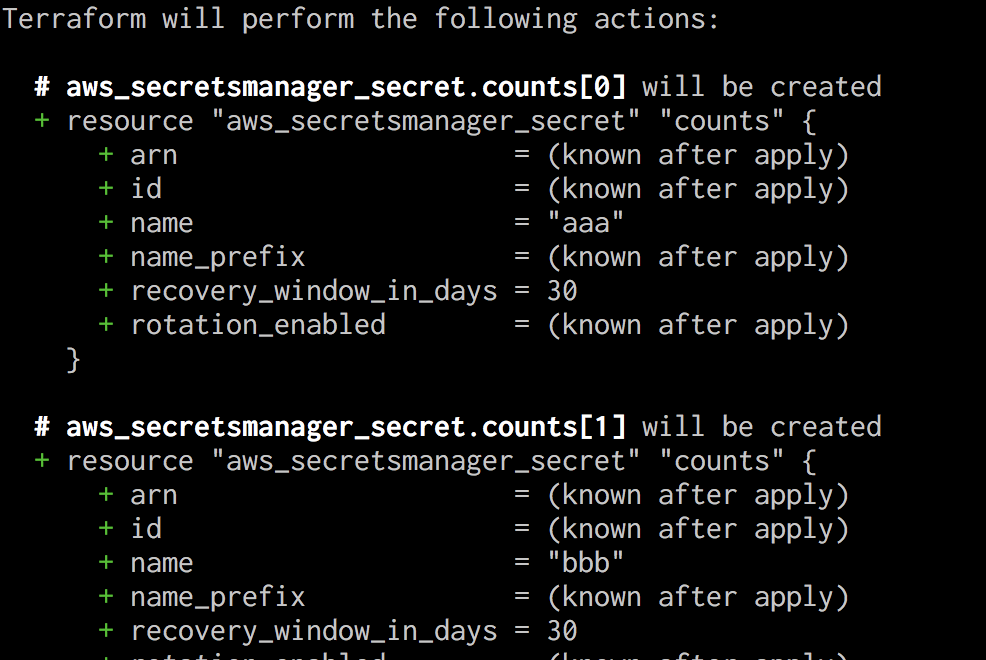
あとはいい感じに shell script にでも編集し直して実行してしまいましょう。
tfstate の編集 - リスト化した場合
注意が必要なのが、もともとバラバラに定義していたリソースを、 count などで一括処理する形へ変更した場合です。この場合、 mv 先は aws_instance.web_servers[0] のようにリストの1要素という形になりますが、この web_servers というリスト自体が tfstate にまだ存在していない状態だと、そのリストへ要素を追加するという処理は実行できません。

対処としては、一旦 count = 0 として、リストを空の状態で terraform apply を実行し、 tfstate へリストを作成した上で mv を実行することになります。
tfstate の直接編集
さて、最後に禁断の tfstate 直接編集についても少し触れておきます。禁断の、と言っても本当に手で編集してほしくなければバイナリにするでも暗号化するでも方法はあると思うので JSON で書くということはそういうことなんでしょう、とは思っています。
とは言ったものの、私は直接 tfstate 編集することはここ2年ぐらいもうやっていないような気がします。 state サブコマンドの実装でかなり状況が改善されつつはあるというのが1つ。それでも編集が必要なケースについては、もう諦めて Terraform を書き直したほうが早いと思っているのが1つ。 tfstate 直接編集はあまりに尖ったスキルすぎて、チーム内での共有などがしづらいというのが1つです。
Terraform が多少乱れたり使い物にならなくなったところで、先述したように import などを上手く使えば、ゼロから作り直すこともできなくはありません。 Martin Fowler が提唱した「犠牲的アーキテクチャー」という考え方がありますが、一旦すべて書き直したほうが結局コストも低く、クオリティも高くなる可能性はあります。 tfstate を直接編集しなければならない状況に追い込まれたら、そのように思考を転換するのも一手かと思います。
どうしても直接編集をする場合は、 terraform state pull > terraform.tfstate で一度ダウンロードしてから編集を行い、完了後に terraform state push terraform.tfstate する形を取ります。編集中は terraform plan -state=terraform.tfstate をこまめに行い、致命的な編集ミスがないことを都度確認することを勧めます。
最後に
自分の経験として、 Terraform を使っていて悩まされる機会が多いのが tfstate です。そこでいくつかプラクティスをまとめて記事にしようと思っていたのですが、いつの間にか分量が膨らみ、どうせならと網羅的な「概論」という形になってしまいました。
tfstate の挙動や背景を知ることで、 Terraform への理解も一層深まると思いますので、ここに書いていないことについても是非深堀りしてみてください。